Many of the ethical questions behind artificial intelligence and machine learning are clear: the issues of bias in datasets, the technically and conceptually difficult concept of fairness, and the existential risks of singularity. Lynne has also suggested over at Moral Guillotines that some ethical issues also exist with regards to labour, teaching, and the position of artists and learners within society. Recently though, the Type-Driven team ran into yet another AI hurdle in their collaborations– carefully curated examples which mis-represent the intelligence of AI systems, and which overstate the robustness of associations within a dataset.
Lynne and Michael recently collaborated on a creative project using a word vectorization system (specifically GloVe, developed at Stanford). The idea of word vectorization (or word embedding) is to map natural language words to mathematical “vectors” (ordered lists of numbers) to make them easier to use in computer systems. For example, vectorization is one of the first steps in processing input for large language models like GPT-4.
A “good” vectorization scheme should not randomly assign words to vectors, but rather preserve some sort of semantics associated with the word. This helps whatever system that is consuming the vectors to have a head-start in whatever language task it is intending to perform (e.g. predict future text, assign positive/negative labels, etc.). To this end, vectorization schemes are themselves generally created using machine learning methods (it’s AI all the way down, except of course where it’s human exploitation doing the teaching). In the case of the model we used, GloVe, it uses an unsupervised learning model based on word pair co-occurrence statistics from a given corpus of text (you can read their paper for more details on how this works).
To illustrate the success of GloVe preserving semantics, the authors of the work give a few examples. First, in the vector space, the nearest neighbors to the word “frog” includes some species of frog. Second, the line between vectors in the space captures certain relationships. They include three examples of this: the line connecting “man” and “woman” also (approximately) connects “king” and “queen”, the line connecting “96817” to “Honolulu” (these are related because the former is a ZIP code in the latter) also (approximately) connects “92804” to “Anaheim” (another correct ZIP pair), and finally the line connecting “strong” to “stronger” also approximately connects “dark” to “darker” (both pairs are related by comparative vs superlative). And to their credit, these examples do look quite impressive!
One way to think of the linear relationships is algebraically, "woman" - "man" is the line connecting “man” and “woman” because the algebraic statement "man" + ("woman" - "man") = "woman" is true. This framing also allows us to generalize these relationships as analogies. The statement “man is to woman as king is to BLANK” can be encoded as "king" + ("woman" - "man") = ?. In this particular example, the model gives “queen” as an answer, which may make it appear to understand some concept of gender.
This usage of the model to create analogies is encouraged by the developers of GloVe as well. They provide code to automate this kind of analysis. You can load up the model and then give it three words representing a “X is to Y as Z is to BLANK” statement, and it will fill in the blank for you.
Lynne and Michael thought it would be cool to use this analogy generation to create an erasure poem. An erasure poem seeks to take a source text (in this case, the output of the vectorization model) and critique said text. Inspired by Lynne’s previous works on the position of artists and laborers in relation to AI, Lynne and Michael decided to try to craft analogies like “art is to algorithm as capitalism is to BLANK”. The model would fill in the blank and then the erasure poem could critique the comparisons it made. The pre-trained model we chose to use for this is the one trained from 2 billion tweets (available for download from the GloVe project website). Unfortunately, this did not work out as well as we hoped.
Although examples such as the “king” and “queen” referenced above seem very nice and neat, they are the exceptions rather than the rule. It turns out that “man” and “woman” are quite close to each other in the vector space and so are “king” and “queen”, therefore a line between “man” and “woman” also being one between “king” and “queen” is not surprising because effectively this line simply hops the the nearest neighbor in the data set. Thinking about this in terms of the statistical nature of the model, it makes sense. In many sentences where the word “man” is used, the word “woman” could be used instead (as we move towards a more equitable society), and similarly for “king” and “queen”. In fact, this idea of two words being similar if and only if they appear in similar sentences is called “distributional semantics” and is the theory behind why we might try these kinds of statistical co-occurrence models in the first place.
This definition of similarity also makes some antonyms appear very close together, for example “up” and “down”. Even though these words mean opposite things, they still tend to appear in the same kinds of sentences: “I’m [up/down] for anything”, “The shop is [up/down] the road from here”, “Take this box [up/down] to the third floor” (which version makes sense depends on what floor we are on now), etc. You might expect the same thing to happen with “left” and “right”, but it turns out the nearest neighbor to “left” is “leave” because “left” could either be the direction or the past tense of “leave”. This fact is a bit of a tangent, but also illustrates the point that the same word having multiple meanings can pose a problem for these models (consider also how “monarch” might relate to “king”/”queen” or to “butterfly”).
When you consider words that do not have obvious replacements, the model entirely breaks down and this is the the problem we encountered when trying to have the model create analogies for us. For example the word “plagiarism” could not be used to generate meaningful analogies because most lines from it pointed off into the vector space void where there were no reasonably close words to it. In fact, there were only three words within 50 units (measured using Euclidean distance): “dishonesty,” “forgery,” and “accusation”. By contrast, other words had hundreds of neighbors within 50 units. Words less common than “plagiarism” have even worse results. For example, the closest neighbors to “zeitgeist” were “addendum,” “redux,” and “ominteraction” (the last of which, does not appear to be a real word at all).
The model failed to generate analogies in almost all cases we tried. The one exception was “Art is to Algorithm as Artist is to Approximation,” which, even as a poet, Lynne was unable to find meaning in.
Ultimately though, we should find this lack of meaning unsurprising given the statistical nature of the model discussed above. Perhaps this is related to the lengths that Chat-GPT and similar large language models will go to confabulate information. Of course, this does not mean that humans can’t create or find meaning there, just as we find meaning in the natural world, astrology, and any other number of idiosyncratic and unintelligent things that are a part of our environment. We were, in the end able to create meaning from the messiness of the data that we found. With some careful, human intelligence working on the problem we came up with the following process.
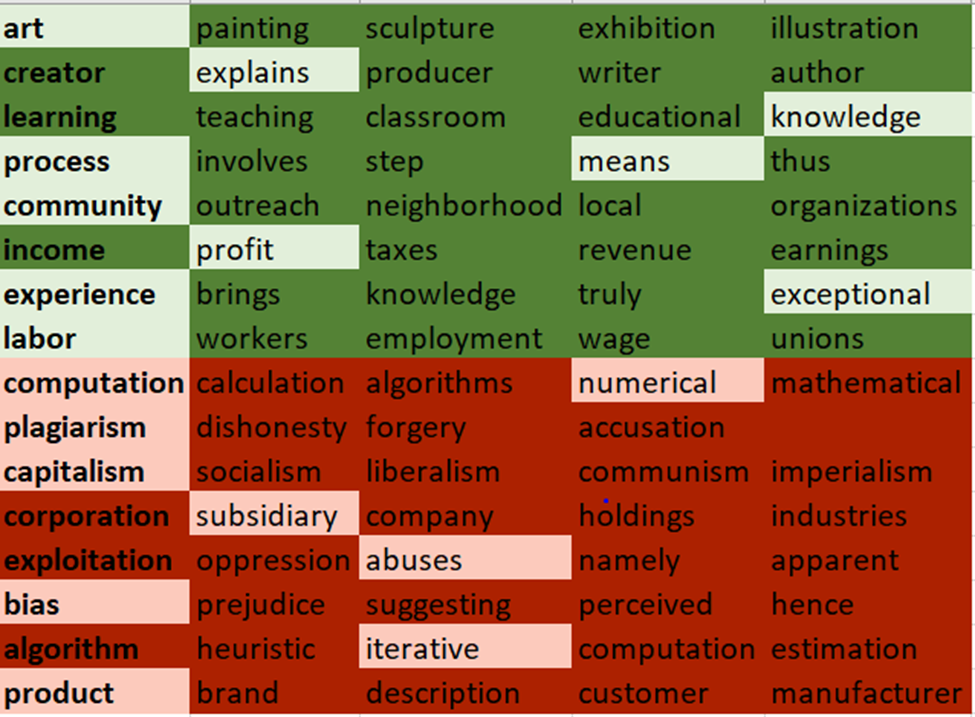
- Create a list of curated words (the bolded, leftmost words).
- Find those words “closest neighbors” within 50 units
- Eliminate unintelligible or repetitive words from the “closest neighbors” list (e.g. hte, painter and painting)
- Further narrow down list of curated words to 8 words on each side of “Art” and “Computation.”
- Organize the rows to allow for poetry to be made, keeping the neighbors with the curated words, and the Art words on the art side, and the Computation words on the computation side.
- Perform erasure. The lighter green and red is what is meant to be read as the erasure. Find the visuals and text below.
Erasure of a Large Language Model: Art vs. Computation, and their associations
art explains knowledge
process means community profit
experience exceptional labour
computation numerical plagiarism
capitalism subsidiary abuses
bias iterative product.
Pingback: Limitations of Machine Learning: Art, Creation, and Misrepresentation – Moral Guillotines